AI Infra学习之旅-第一个vLLM程序
前言
今天是我正式开始学习 AI Infrastructure 的第一天。作为一个对大模型推理充满好奇的初学者,我决定从实战开始——在免费的 Kaggle GPU 上运行 vLLM。这篇文章记录了我从零开始的完整过程,希望能帮助到和我一样的新手。
核心目标: 今天就跑通第一个 vLLM 程序!
为什么选择 Kaggle + vLLM?
在开始之前,我做了一些调研:
为什么选择 Kaggle?
- ✅ 完全免费: 每周 30 小时 GPU 时间
- ✅ 无需配置: 预装了常用的深度学习库
- ✅ P100 GPU: 16GB 显存,足够运行中小型模型
- ✅ 入门友好: 无需本地 GPU,浏览器即可使用
为什么选择 vLLM?
- ✅ 高性能: 比 HuggingFace Transformers 快数倍
- ✅ 易用性: API 设计简洁,上手快
- ✅ 工业级: 被多个公司用于生产环境
- ✅ 学习价值: 涉及 PagedAttention 等前沿技术
实战步骤
Step 1: 注册 Kaggle 账号
这一步非常简单:
- 访问 Kaggle 官网
- 使用 Google 账号快速注册
- 重要: 验证手机号(这是使用 GPU 的必要条件,也可以使用Persona进行验证)
Step 2: 创建 GPU Notebook
创建 Notebook 的步骤:
- 点击右上角 “Create” → “New Notebook”
- 在右侧设置面板中:
- Accelerator → 选择
GPU P100✅ - Internet → 打开
On✅
- Accelerator → 选择
- 等待环境启动(大约 30 秒)
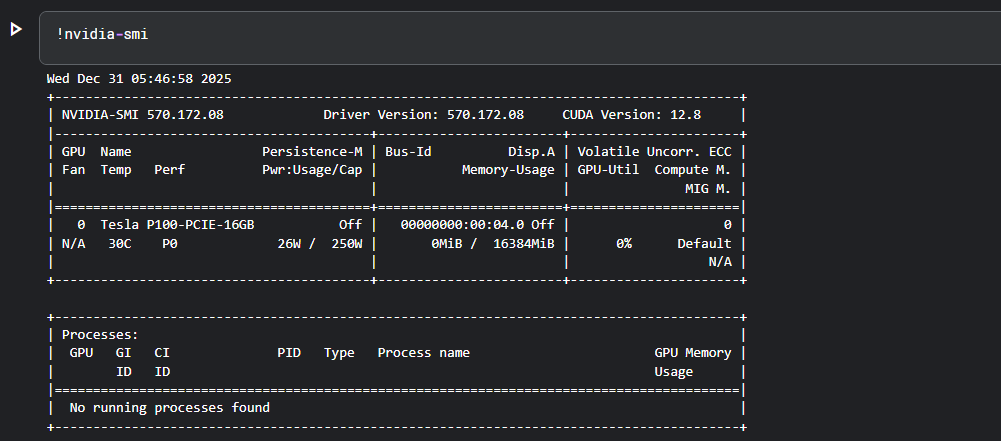
启动后,在第一个 cell 中运行以下命令验证 GPU:
1 | !nvidia-smi |
如果看到类似以下输出,说明 GPU 环境已就绪:
1 | +-----------------------------------------------------------------------------+ |
Step 3: 安装 vLLM
在新的 cell 中运行:
1 | # 安装 vLLM |
安装可能需要 10-15 分钟,请耐心等待。安装完成后,你应该看到类似的输出:
1 | ✅ vLLM 安装成功!版本: 0.x.x |
Step 4: 运行第一个推理程序
这是今天的重头戏!我使用 facebook/opt-125m 这个小模型进行测试(只有 125M 参数,加载速度快)。
完整代码如下:
1 | from vllm import LLM, SamplingParams |
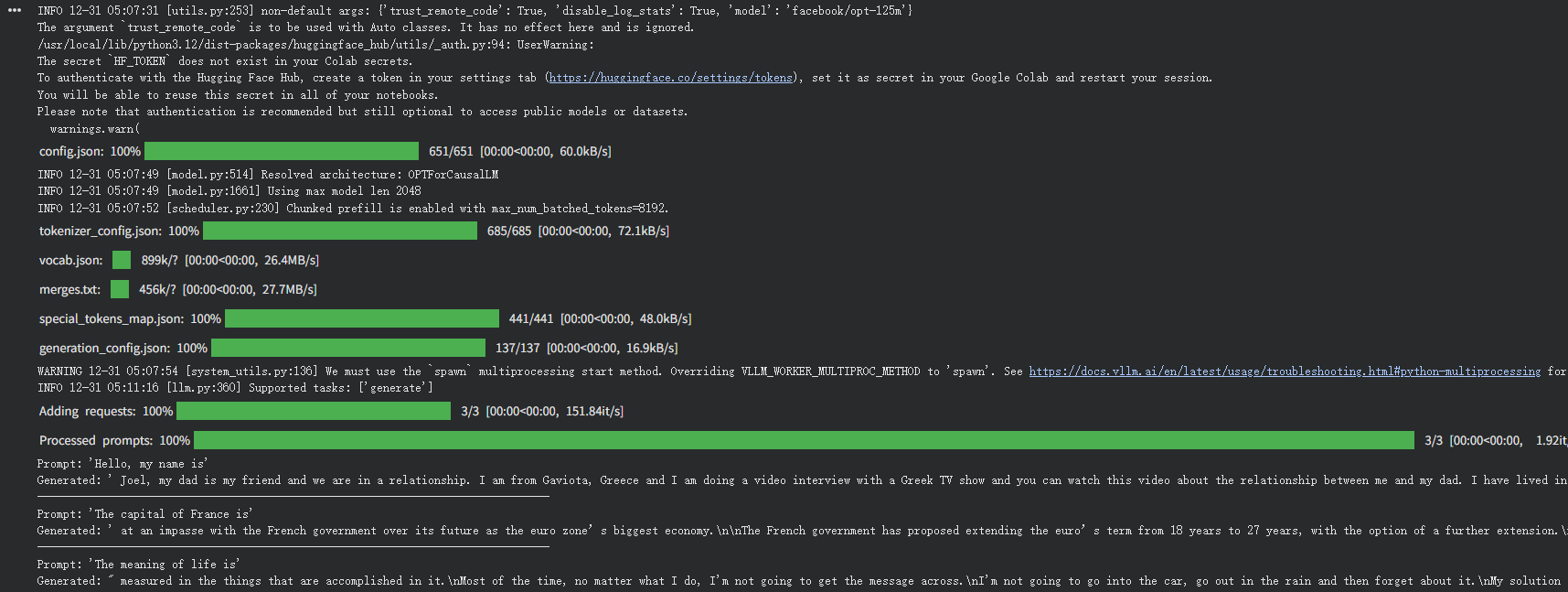
我的运行结果:
2
3
4
5
6
7
8
Generated: ' Joel, my dad is my friend and we are in a relationship...
-------------------------------------------------
Prompt: 'The capital of France is'
Generated: ' at an impasse with the French government over its future as the euro zone’s biggest economy...
-------------------------------------------------
Prompt: 'The meaning of life is'
Generated: " measured in the things that are accomplished in it.\nMost of the time...
Step 5: 性能测试
为了了解 vLLM 的性能,我运行了一个简单的吞吐量测试:
1 | import time |
我的性能数据:

指标 数值 模型 OPT-125M GPU Kaggle P100 总耗时 0.58 秒 总 Token 数 892 吞吐量 1539.24 tokens/秒
踩过的坑与解决方案
问题 1: Kaggle GPU 不可用
现象: 设置中看不到 GPU 选项
原因: 没有验证手机号
解决: 在账号设置中完成手机验证
问题 2: vLLM 安装超时
现象: pip install vllm 一直卡住
解决: 重启 Notebook,或者切换到 Google Colab
问题 3: 模型下载速度慢
现象: 加载模型时长时间无响应
解决: 使用 HuggingFace 镜像站
1 | import os |
写在最后
第一天的学习让我深刻体会到:AI Infrastructure 并不遥远,动手实践才是最好的老师。
如果你也想开始学习 AI Infra,我的建议是:
- 不要被理论吓倒 - 先跑起来,再慢慢理解
- 选择免费资源 - Kaggle/Colab 足够初学者使用
- 从小模型开始 - 125M 参数的模型几秒就能加载
- 记录每一步 - 写博客是最好的复习方式
记住: 慢一点没关系,停下来才可惜。💪
参考资料
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Smarter's blog!
相关推荐


评论
