AI Infra学习之旅-Transformer详解
Transformer深度解析:从零开始理解"注意力就是你所需要的一切"
如果你关注AI领域,ChatGPT、BERT、GPT这些名字应该不陌生。它们背后有个共同的"老祖宗"——Transformer。我最初看到这个架构时,觉得有点复杂,但当我真正理解了它的设计思想后,突然发现一切都说得通了。今天我想用最直白的方式,和你聊聊这个改变了整个深度学习游戏规则的架构。
写在前面
2017年,Google的研究团队发了一篇论文,标题叫《Attention Is All You Need》。第一次看到这个标题时我就觉得,这帮人可真敢说——“注意力就是你所需要的一切”,口气未免太大了吧?但几年过去了,事实证明他们是对的。这篇论文提出的Transformer架构,不仅彻底改写了NLP的规则,还渗透到了CV、语音、甚至生物信息学等各个领域。
在扎进技术细节之前,我想先说说Transformer为什么会出现。毕竟,任何技术的诞生都是为了解决某个实际问题。
一、RNN的困境:我们为什么需要新架构?
在Transformer横空出世之前,处理序列数据(比如文本、语音)的主流方案是RNN(循环神经网络)以及它的改进版LSTM、GRU。
RNN怎么工作的?
你可以把RNN想象成这样一个场景:你在读一本侦探小说。RNN的处理方式就是一个字一个字地往下读,每读一个字都会更新对剧情的理解。
1 | 输入: "我 爱 北京 天安门" |
听起来挺合理的,对吧?但这里有个致命的问题:必须按顺序处理,没法跳着来。
RNN的两大硬伤
1. 没法并行计算
要处理第3个词,你必须先把第1、2个词处理完。这就像高速公路只有一条车道,不管你有多少辆车(GPU核心),也只能排队一辆一辆过。对于动辄几百万、上亿参数的模型来说,这种串行处理简直是灾难。训练一个大模型可能要好几周,谁受得了?
2. 长距离依赖问题
来看这个句子:
“那只猫,它在花园里追蝴蝶的时候不小心撞到了树,后来躺在沙发上休息了一下午,最后终于恢复了精神,它开心地喵喵叫。”
你肯定一眼就能看出最后的"它"指的是开头的"猫"。但对RNN来说,这可太难了。"猫"这个信息得像接力赛一样,一站一站地传到"它"那里。传递链越长,信息损失越严重——就像小时候玩传话游戏,传到最后往往都变味了。
理论上LSTM通过门控机制缓解了这个问题,但也只是"缓解",并没有根治。
Transformer的出现,就是为了一刀切掉这两个问题。
二、注意力机制:Transformer的核心武器
在正式拆解Transformer之前,得先搞懂它最核心的部分——自注意力机制(Self-Attention)。这东西听起来玄乎,其实思想很直观。
先来个直观的例子
假设有这么一句话:
“那只动物没能过马路,因为它太累了。”
当你读到"它"的时候,你的大脑会做什么?会自动"回看"前面的内容,判断"它"指的是啥。你会把更多注意力分配给"动物",而不是"马路"或"因为"。
自注意力机制做的就是这件事:在处理每个词的时候,让模型能"看到"句子里所有其他词,并自动决定该给每个词分配多少注意力。
Query、Key、Value:三个关键角色
自注意力的实现靠三个向量:Query(查询)、Key(键)、Value(值)。
我第一次看到这三个概念时也很懵,后来发现用图书馆来比喻特别好理解:
- Query:你想找的书的描述,比如"关于深度学习的入门书"
- Key:每本书的标签/索引,比如"深度学习"、“CV”、“烹饪”
- Value:书的实际内容
找书的过程是这样的:
- 拿着你的Query(需求描述),去和书架上每本书的Key(标签)对比
- 标签越匹配,说明这本书越相关
- 根据相关性高低,从对应的Value(书的内容)中提取信息
- 最后你得到的是一个"混合信息"——相关性高的书提供更多内容,相关性低的书提供较少内容
在Transformer里,每个词都会生成自己的Q、K、V向量。这些向量怎么来的?很简单,就是把词向量和三个可学习的权重矩阵相乘:
1 | Q = 词向量 × Wq |
这三个矩阵Wq、Wk、Wv是模型训练过程中学习出来的。
注意力分数怎么算?
有了Q、K、V,注意力的计算就是四步走:
第一步:计算相关性分数
用当前词的Query和所有词(包括自己)的Key做点积。点积值越大,说明两个词越相关。
1 | 分数 = Q · K^T |
这里为什么用点积?因为点积本质上衡量的是两个向量的相似度。方向越接近,点积越大。
第二步:缩放(Scaling)
直接用点积会有个问题:如果向量维度很大(比如512维),点积的结果也会很大。这些大数值经过softmax后,会导致梯度极小(想象一下softmax把一个很大的数映射成接近1,其他数映射成接近0,梯度基本就没了)。
所以论文里做了个简单粗暴的处理:除以√dk(Key向量维度的平方根)。
1 | 缩放后的分数 = Q·K^T / √dk |
为什么是平方根?论文附录里有数学推导,简单说就是:假设Q和K的每个元素均值为0、方差为1,那么d维向量点积的方差就是d。除以√d可以把方差拉回到1,保持数值稳定。
第三步:Softmax归一化
把分数转成概率分布,让所有注意力权重加起来等于1。
1 | 注意力权重 = softmax(缩放后的分数) |
经过softmax后,相关性高的词得到更大的权重,相关性低的词权重接近0。
第四步:加权求和
用注意力权重对所有Value向量进行加权求和。
1 | 输出 = 注意力权重 × V |
整个过程可以用一个公式搞定:
1 | Attention(Q, K, V) = softmax(QK^T / √dk) × V |
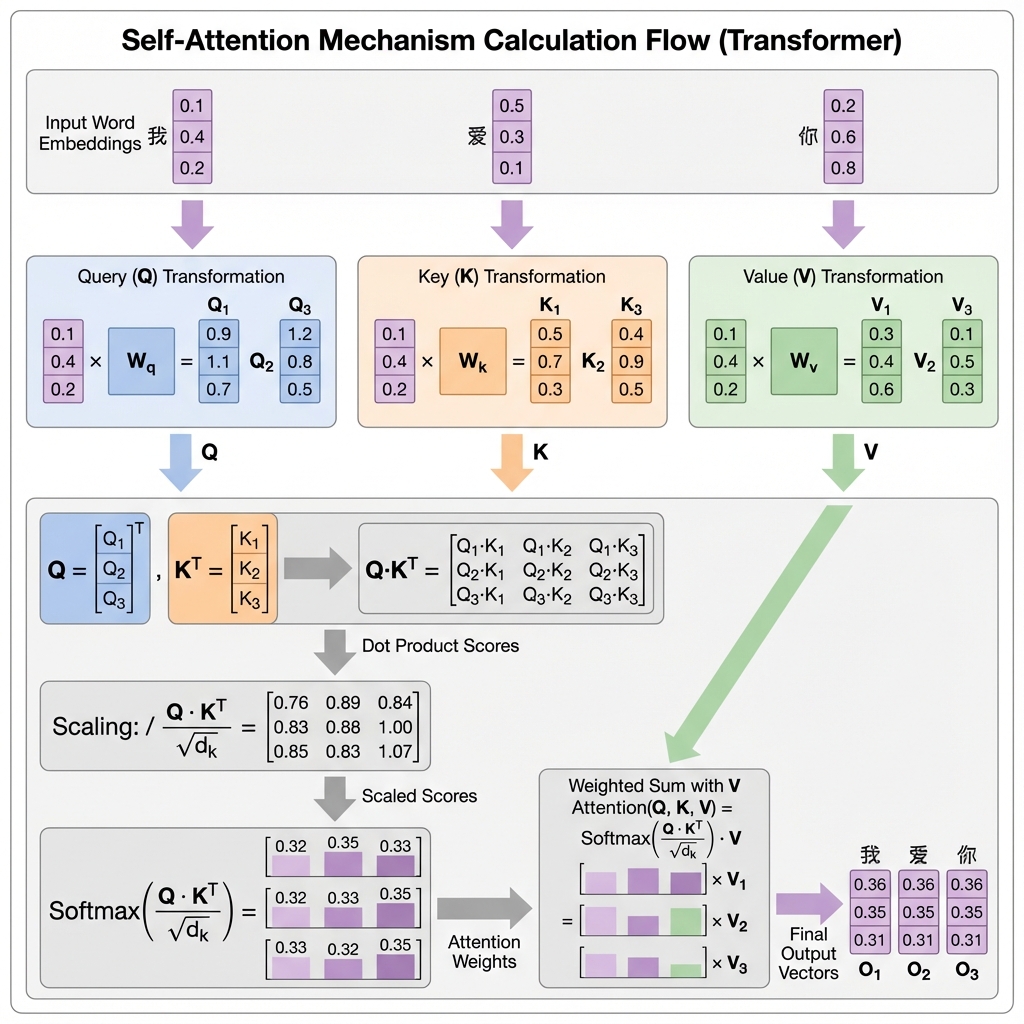
来个具体例子
假设我们有三个词:“我”、“爱”、“你”,每个词的向量是2维(实际中通常是512维或更高,这里为了方便演示用2维)。
假设"爱"这个词的Query是[1, 0],三个词的Key分别是:
- “我”:
[0.8, 0.2] - “爱”:
[1.0, 0.0] - “你”:
[0.6, 0.5]
计算"爱"对三个词的注意力:
-
计算点积:
- 爱→我:1×0.8 + 0×0.2 = 0.8
- 爱→爱:1×1.0 + 0×0.0 = 1.0
- 爱→你:1×0.6 + 0×0.5 = 0.6
-
缩放(√2 ≈ 1.41):
- 爱→我:0.8/1.41 ≈ 0.57
- 爱→爱:1.0/1.41 ≈ 0.71
- 爱→你:0.6/1.41 ≈ 0.42
-
Softmax后大约是:
- 爱→我:0.31
- 爱→爱:0.38
- 爱→你:0.31
-
用这些权重对Value向量加权求和,得到"爱"的新表示
这个例子说明,“爱"这个词对自己的注意力最高(0.38),但也会关注"我"和"你”(各0.31左右)。这很合理,因为动词往往需要同时关注主语和宾语。
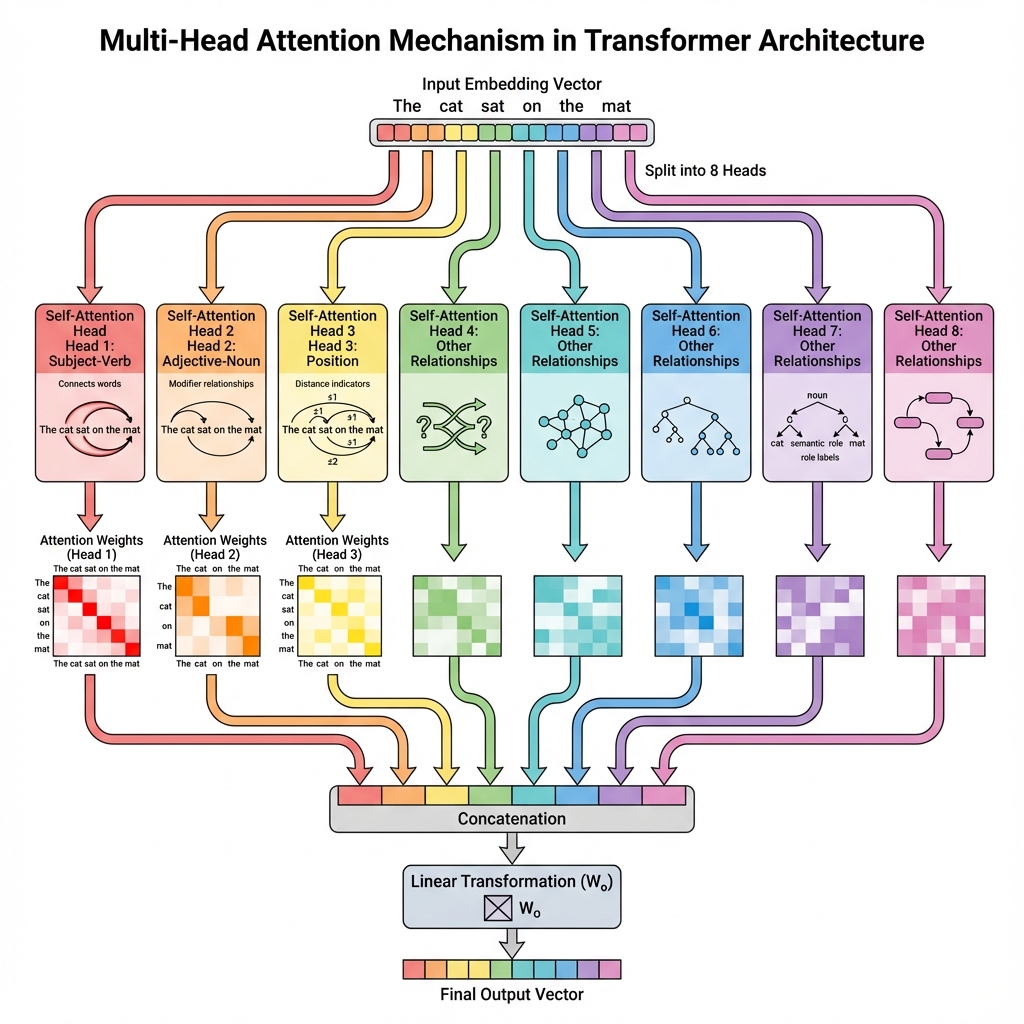
多头注意力:从多个视角看问题
单个注意力机制就像从一个角度看东西。但理解一句话,可能需要同时考虑语法结构、语义关系、指代关系等多个维度。
多头注意力(Multi-Head Attention) 就是这个思路:
- 把Q、K、V分别切成多个"头"(原论文用了8个头)
- 每个头独立计算注意力
- 把所有头的结果拼起来,再做一次线性变换
1 | MultiHead(Q,K,V) = Concat(head₁, head₂, ..., head₈) × Wo |
每个头有自己独立的Wq、Wk、Wv权重矩阵,所以能学到不同类型的关系。
举个例子,在翻译句子时:
- 第1个头可能专注于主谓关系
- 第2个头可能专注于修饰关系(形容词和名词)
- 第3个头可能专注于位置关系(前后词的相对位置)
- …
把这些不同视角的信息综合起来,模型对句子的理解就更全面了。
三、Transformer架构全貌
搞懂了注意力机制,就理解了Transformer的核心。现在我们把整个架构拼起来。
Transformer采用经典的编码器-解码器(Encoder-Decoder) 结构,左边是Encoder,右边是Decoder。
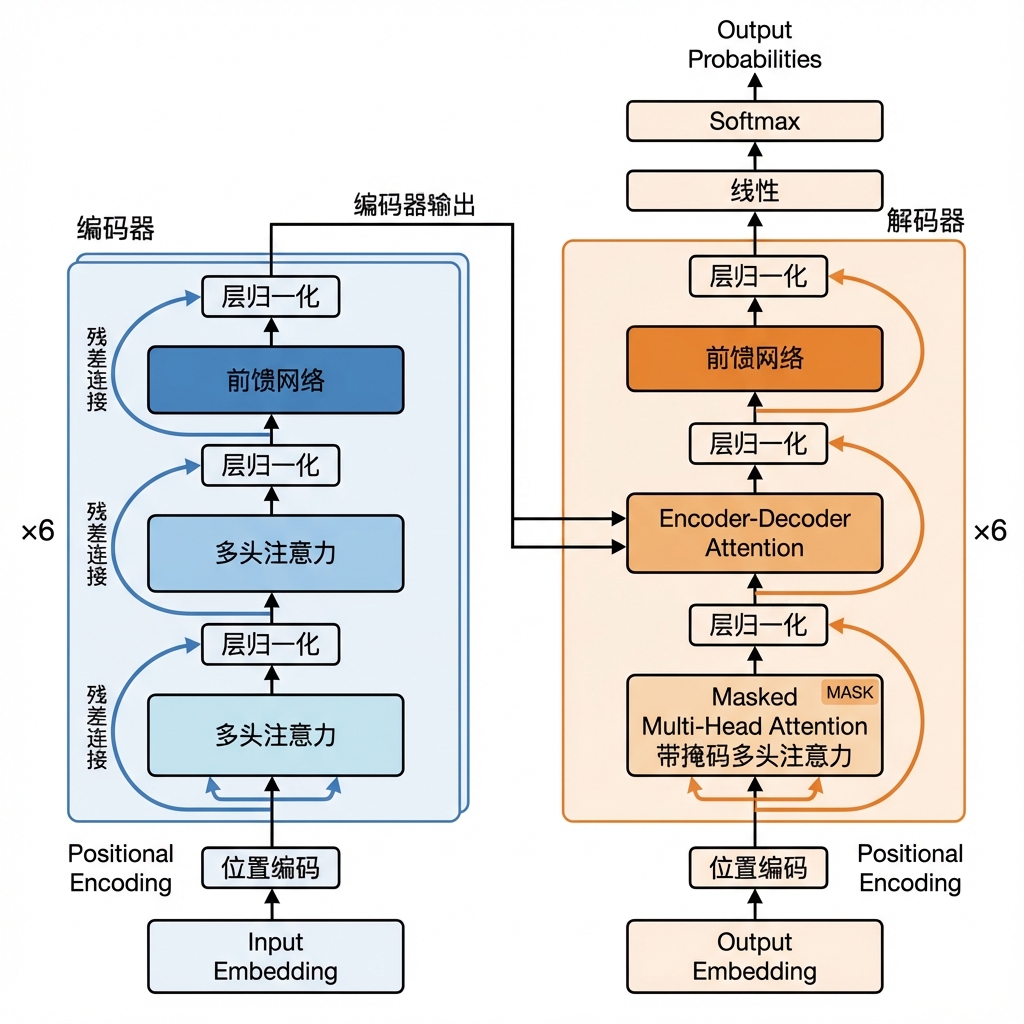
原论文中的Transformer由6层Encoder和6层Decoder堆叠而成。
编码器(Encoder)
每一层Encoder包含两个子层:
- 多头自注意力层:让每个词都能"看到"输入序列中的所有其他词
- 前馈神经网络(FFN):其实就是两层全连接网络,对每个位置的表示做进一步变换
关键的是,每个子层都包了两个"保护壳":
- 残差连接(Residual Connection):把输入直接加到输出上,这样梯度可以"直通"回去,缓解深层网络的梯度消失问题
- 层归一化(Layer Normalization):把每一层的输出归一化,稳定训练过程
整个流程可以写成:
1 | 输出 = LayerNorm(x + SubLayer(x)) |
先对x做变换(MultiHead Attention或FFN),然后和原来的x相加(残差连接),最后归一化。
6层Encoder叠在一起,就像是对输入做了6次"提炼",每一层都在之前的基础上提取更抽象的特征。
解码器(Decoder)
解码器比编码器多一个子层,总共三个:
- 带掩码的多头自注意力层(Masked Multi-Head Attention)
- 编码器-解码器注意力层(Cross-Attention):让解码器能够"查阅"编码器的输出
- 前馈神经网络
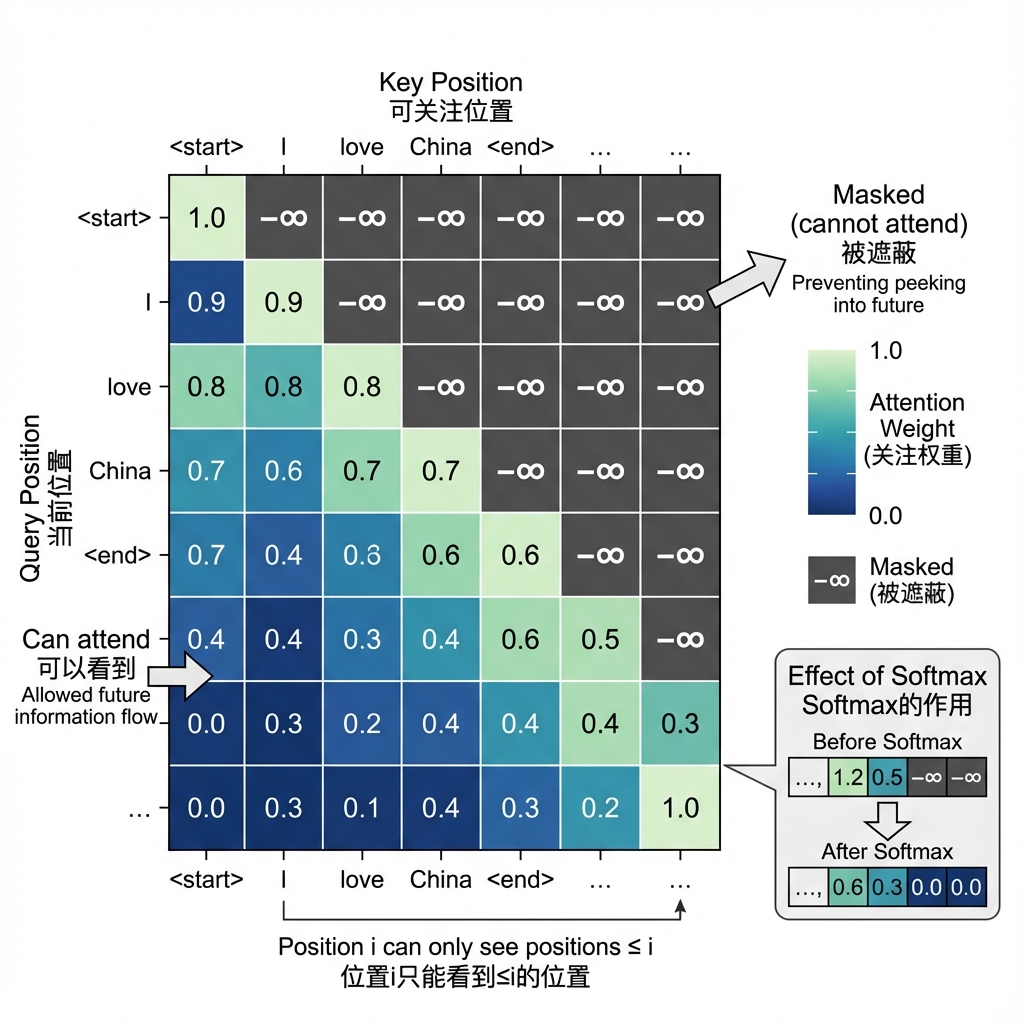
为什么需要掩码(Mask)?
这是个关键问题。在训练翻译模型时,我们已经有了完整的目标句子。比如把"我爱中国"翻译成"I love China",训练时我们知道完整的目标是"I love China"。
但我们希望模型学会的是:根据已生成的词,预测下一个词。如果模型在预测"love"的时候能"偷看"到后面的"China",那就作弊了——测试时哪有未来的词给你看啊?
掩码的作用就是在自注意力计算时,遮住未来位置的信息。具体做法是:在softmax之前,把未来位置的分数设为负无穷(-∞)。这样经过softmax后,那些位置的注意力权重就变成0了。
比如在生成"love"时:
- 可以看到
<start>和"I" - 看不到"love"后面的"China"
编码器-解码器注意力
这是Decoder特有的第二个子层。它让解码器在生成每个词时,可以"查阅"编码器的输出。
这里的Query来自解码器,Key和Value来自编码器。这样解码器就能根据自己当前的状态(Query),去编码后的源句子里找相关信息(Key),并提取相应内容(Value)。
比如翻译"我爱中国"→"I love China"时:
- 生成"I"时,主要关注"我"
- 生成"love"时,主要关注"爱"
- 生成"China"时,主要关注"中国"
当然,实际情况会更复杂,因为不是所有语言都是一一对应的词序。
位置编码:告诉模型词的顺序
自注意力有个"缺陷":它是位置无关的。
什么意思?对于自注意力来说,"我爱你"和"你爱我"如果只看词本身,处理方式是一样的——因为它只计算词与词之间的关系,不管它们的位置。
但词的位置显然很重要啊!"狗咬人"和"人咬狗"完全是两码事。
怎么办?把位置信息"编码"进输入向量里。
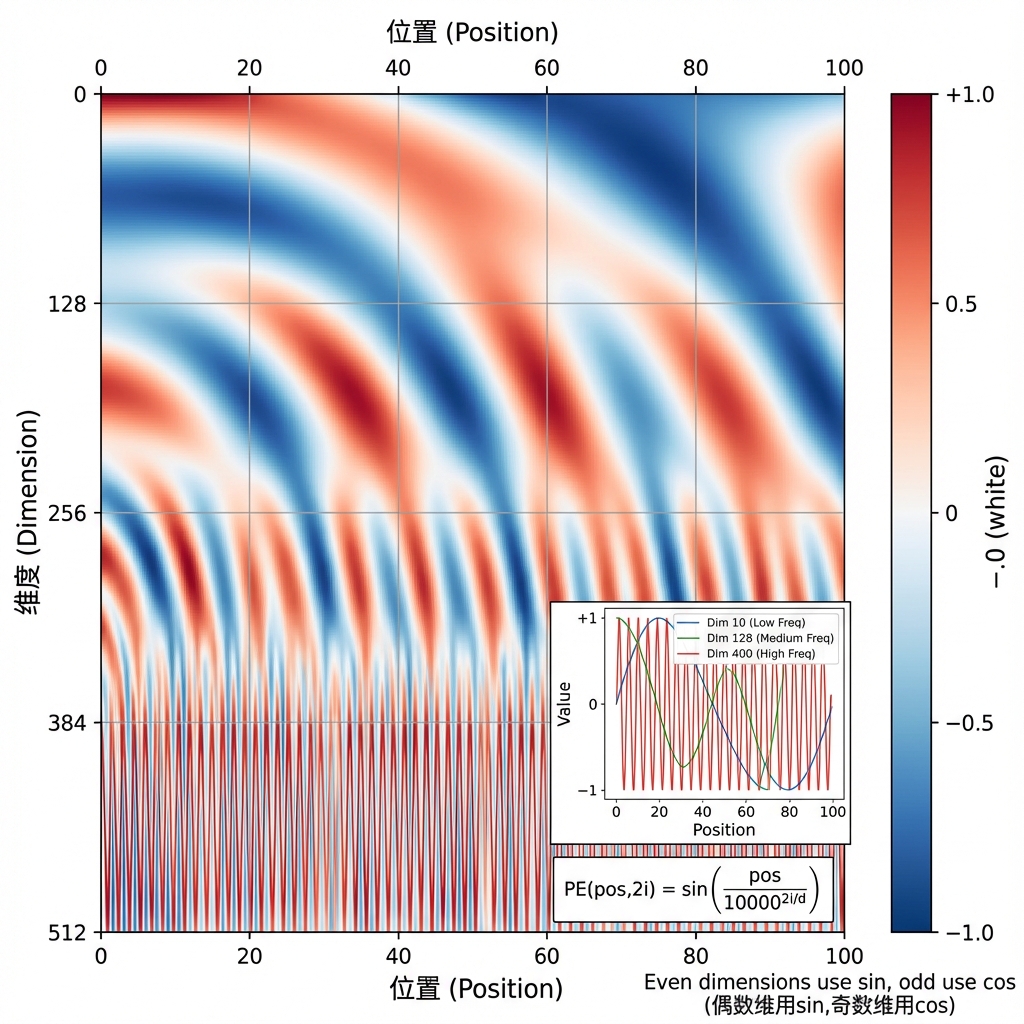
位置编码(Positional Encoding) 用正弦和余弦函数生成:
1 | PE(pos, 2i) = sin(pos / 10000^(2i/d)) |
其中:
pos是词在句子中的位置(0, 1, 2, …)i是维度索引(0到d/2)d是向量维度(比如512)
为什么用正弦/余弦函数?主要是因为它们有几个好性质:
- 值域有界:始终在[-1, 1]之间,不会因为位置太大而爆炸
- 每个位置唯一:不同位置的编码不会重复
- 能表示相对位置:利用三角函数的性质,PE(pos+k)可以表示为PE(pos)的线性组合,这让模型更容易学到"相对位置关系"(比如"前面第2个词")
- 可以泛化到更长序列:训练时见过100个词的句子,测试时来了150个词,位置编码依然能算出来
位置编码会直接加到词嵌入向量上,作为模型的最终输入。
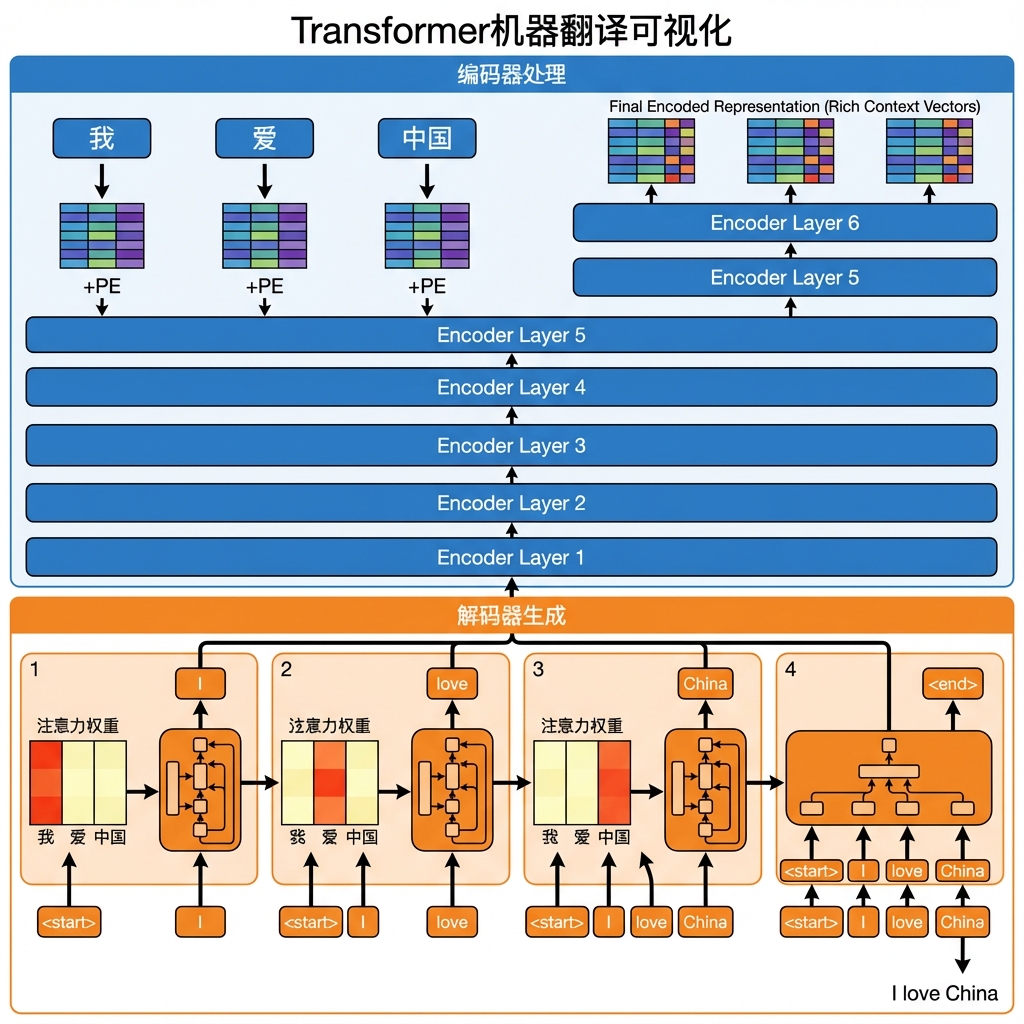
四、实际应用:机器翻译的完整流程
理论说了一堆,我们来看个具体例子。假设要把"我爱中国"翻译成"I love China"。
编码阶段
第一步:输入表示
- 把"我"、“爱”、"中国"转成词向量(比如用Word2Vec或直接学习Embedding)
- 给每个词向量加上位置编码("我"是位置0,"爱"是位置1,"中国"是位置2)
第二步:经过6层Encoder
- 第1层:通过自注意力,“爱"这个词能看到"我"和"中国”,理解到这是个主谓宾结构
- 第2层:在第1层的基础上进一步提炼,可能学到"我爱X"这种情感表达模式
- …
- 第6层:得到包含丰富上下文信息的最终编码
每经过一层,词的表示就更"丰富"一些,包含的上下文信息就更多一些。
解码阶段
第一步:开始标记
输入<start>标记,告诉模型"该生成句子了"。
第二步:生成"I"
- 解码器接收
<start> - 通过掩码自注意力处理
<start>(虽然只有一个词,也要走这个流程) - 通过编码器-解码器注意力,关注编码后的源句子,发现"我"最相关
- 经过FFN,输出一个概率分布
- 概率最高的词是"I"
第三步:生成"love"
- 解码器接收
<start> I - 掩码确保"I"只能看到自己和
<start>,看不到未来 - 再次查阅编码器输出,这次主要关注"爱"
- 预测下一个词:“love”
第四步:生成"China"
- 解码器接收
<start> I love - 关注编码器中的"中国"
- 预测:“China”
第五步:结束
- 解码器接收
<start> I love China - 预测下一个词是
<end>,翻译结束
实际使用中,我们不一定每次都选概率最高的词(这叫Greedy Decoding),更常用Beam Search:保留top-k个候选序列,最后选总概率最高的那个。
五、为什么Transformer这么成功?
回顾一下,Transformer为什么能在短短几年内席卷整个AI领域?
1. 真·并行计算
这是最直接的优势。RNN必须一个词一个词地算,Transformer可以一次性算完整个句子。
假设一个句子有100个词,RNN需要100步串行计算;Transformer可以一步算完所有词的self-attention(当然内部还是有矩阵运算,但这些可以完美并行)。
在GPU上,这个优势太明显了。GPU有成千上万个核心,就是为并行计算设计的。Transformer充分发挥了硬件优势,训练速度比RNN快了几个数量级。
2. 长距离依赖不再是问题
在Transformer里,任意两个词之间的"距离"都是1——一次注意力计算就能直接建立联系。
不像RNN,信息要一站一站传递。句子开头的词,要传100步才能影响结尾的词;Transformer里,开头直接看到结尾。
这让模型能轻松捕捉长距离依赖,比如指代消解、长篇文档的主题理解等。
3. 可解释性更好
注意力权重可以可视化。你可以画个热力图,看到模型在翻译"China"时,把80%的注意力放在了源句子的"中国"上。
这比RNN的隐状态好理解多了。RNN的隐状态是一堆数字,你根本不知道它记住了啥、忘了啥。
4. 极强的可扩展性
Transformer的架构非常"scalable"。想要更强的模型?简单:
- 加深:6层→12层→24层→96层
- 加宽:512维→1024维→2048维
- 加头:8 heads→16 heads→32 heads
从BERT-base(110M参数)到GPT-3(175B参数),再到最新的模型(千亿级),都是Transformer架构。只是层数、维度不同而已。
而且有个神奇的现象:参数越大,效果往往越好(当然数据也要跟上)。这就是大模型时代的基石。
六、Transformer的后代们
Transformer提出后,基于它的各种变体和改进模型层出不穷。这里介绍几个最有影响力的:
| 模型 | 架构 | 特点 | 典型应用 |
|---|---|---|---|
| BERT | 只用Encoder | 双向编码,擅长理解文本 | 搜索引擎、问答系统、文本分类 |
| GPT系列 | 只用Decoder | 自回归生成,擅长创造文本 | ChatGPT、代码生成、创意写作 |
| T5 | 完整Encoder-Decoder | 把所有NLP任务都转成"文本到文本" | 翻译、摘要、QA统一框架 |
| Vision Transformer (ViT) | Encoder-only | 把图像切成patch当词处理 | 图像分类、目标检测 |
| DALL-E / Stable Diffusion | 改进的Transformer | 文生图、多模态 | AI绘画、图像编辑 |
BERT vs GPT:一个理解,一个生成
-
BERT:只用Encoder,训练时随机遮住一些词让模型猜(Masked Language Modeling)。因为能同时看到上下文,所以擅长"理解"任务——给它一篇文章,它能告诉你情感是正面还是负面,能回答文章相关问题。
-
GPT:只用Decoder,训练时根据前面的词预测下一个词。因为只能看到之前的内容,所以擅长"生成"任务——给它一个开头,它能续写出连贯的文章。
这也解释了为什么ChatGPT用的是GPT架构,而不是BERT——因为聊天需要生成回复嘛。
可以说,现代AI的大部分突破,都直接或间接站在Transformer的肩膀上。
写在最后
回头看看我们都聊了些啥:
- 为什么需要Transformer:RNN的并行化困难和长距离依赖问题
- 核心机制:Self-Attention通过Query、Key、Value实现对上下文的灵活建模
- 多头注意力:从多个角度理解输入
- 整体架构:Encoder-Decoder结构,加上位置编码、残差连接、层归一化等关键组件
- 实际应用:翻译、生成、理解,无所不能的基础架构
Transformer的影响已经远超当初的机器翻译。从ChatGPT到Stable Diffusion,从AlphaFold到代码补全工具GitHub Copilot,Transformer无处不在。
说实话,当初读论文时,我没想到这个架构能火成现在这样。它并不完美——比如注意力的O(n²)复杂度在处理超长序列时还是个问题——但它的设计思想实在太优雅了。用注意力机制让模型自己决定关注什么,这个想法简单却强大。
如果你想深入学习AI,Transformer绝对是绕不过去的一关。理解了它,你就掌握了现代AI的基石。
希望这篇文章能帮你建立起对Transformer的直观理解。如果有任何疑问,欢迎留言讨论!
参考资料
- Vaswani, A., et al. (2017). “Attention is all you need.” Advances in Neural Information Processing Systems. 原论文链接
- The Illustrated Transformer - Jay Alammar 的可视化教程,强烈推荐:http://jalammar.github.io/illustrated-transformer/
- Annotated Transformer - Harvard NLP的带注释实现,适合动手实践:https://nlp.seas.harvard.edu/annotated-transformer/
- BERT论文: Devlin, J., et al. (2018). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.”
- GPT-3论文: Brown, T., et al. (2020). “Language Models are Few-Shot Learners.”

