AI Infra学习之旅-PagedAttention详解
PagedAttention:大语言模型推理的内存管理革命
借鉴操作系统虚拟内存思想,实现LLM推理的高效KV Cache管理
引言
在大语言模型(LLM)快速发展的今天,如何高效地进行模型推理成为了一个关键问题。随着模型规模的不断扩大,内存管理成为制约推理性能的重要瓶颈。本文将深入介绍PagedAttention技术——一种受操作系统虚拟内存管理启发的创新性内存管理方法,它极大地提升了LLM推理的效率和throughput。
一、背景:LLM推理中的内存挑战
1.1 KV Cache的作用
在Transformer架构的自回归生成过程中,每个token的生成都需要用到之前所有token的Key和Value向量。为了避免重复计算,这些K、V向量会被缓存起来,这就是KV Cache。
1 | 输入序列: "今天天气" |
1.2 传统方法的问题
传统的KV Cache管理方法存在严重的内存浪费问题:

-
外部碎片化(External Fragmentation)
- 必须为每个请求预先分配一个连续的内存块
- 由于无法预知生成序列的最终长度,通常按最大序列长度分配
- 实际使用长度远小于分配长度时,造成大量浪费
-
内部碎片化(Internal Fragmentation)
- 批处理中不同请求的序列长度不同
- 必须按批次中最长序列分配内存
- 短序列的剩余空间无法被其他请求使用
研究表明,传统方法的内存浪费率高达60%-80%,这严重限制了批处理大小和系统吞吐量。
graph LR
subgraph 传统方法
A[请求1] --> B[预分配大块连续内存]
A2[请求2] --> B2[预分配大块连续内存]
B --> C[大量浪费:60-80%]
B2 --> C
end
subgraph PagedAttention
D[请求1] --> E[按需分配小块]
D2[请求2] --> E2[按需分配小块]
E --> F[极少浪费:<4%]
E2 --> F
end
style C fill:#FFB6C1
style F fill:#90EE90二、PagedAttention核心原理
2.1 操作系统的启发
PagedAttention的设计灵感来源于操作系统中的虚拟内存分页机制:
| 操作系统虚拟内存 | PagedAttention |
|---|---|
| 虚拟内存页 | 逻辑KV块 |
| 物理内存页 | 物理KV块 |
| 页表 | 块表(Block Table) |
| 按需分页 | 动态块分配 |
| 写时复制 | KV块共享 |
2.2 核心设计
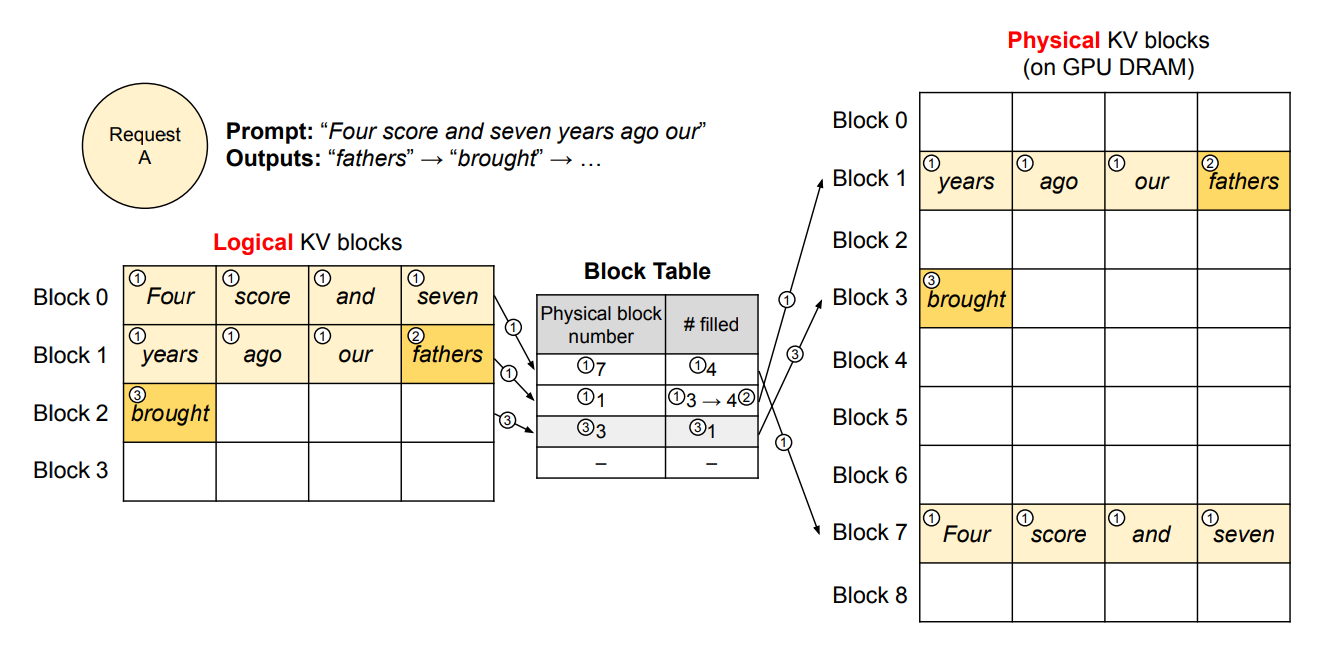
2.2.1 块状存储
PagedAttention将KV Cache划分为固定大小的块(Block):
- 每个块存储固定数量token的KV向量(通常16-128个token)
- 块可以在物理内存中非连续存储
- 每个序列的KV Cache由多个块组成
1 | 逻辑序列: [Token1, Token2, ..., Token100] |
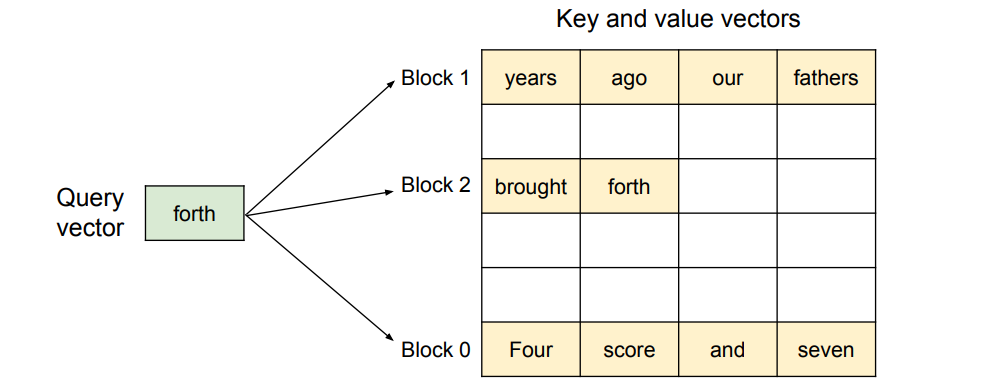
2.2.2 块表映射
每个序列维护一个块表(Block Table),记录逻辑块到物理块的映射:
1 | # 伪代码示例 |
2.2.3 动态分配
- 按需分配:只在需要时分配新块
- 精细粒度:以块为单位分配,而非整个序列
- 即时回收:序列完成后立即释放所有块
2.3 Attention计算的适配
在PagedAttention中,Attention计算需要根据块表来访问KV Cache:
1 | # 传统Attention(伪代码) |
三、PagedAttention的关键优势
3.1 近乎零的内存浪费
通过块状动态分配,PagedAttention实现了:
- 外部碎片 ≈ 0:无需预分配最大长度
- 内部碎片 < 4%:只有最后一个未满的块存在浪费
这将内存利用率从传统的20-40%提升到96%以上!
3.2 高吞吐量提升
更高的内存利用率意味着:
- 可以容纳更大的批处理大小
- GPU利用率显著提升
- 系统吞吐量提升2-24倍
| 对比系统 | 吞吐量提升 |
|---|---|
| HuggingFace Transformers | 24x |
| FasterTransformer | 3.5x |
| Orca | 2-4x |
3.3 高效的内存共享
PagedAttention支持多种场景下的KV Cache共享:
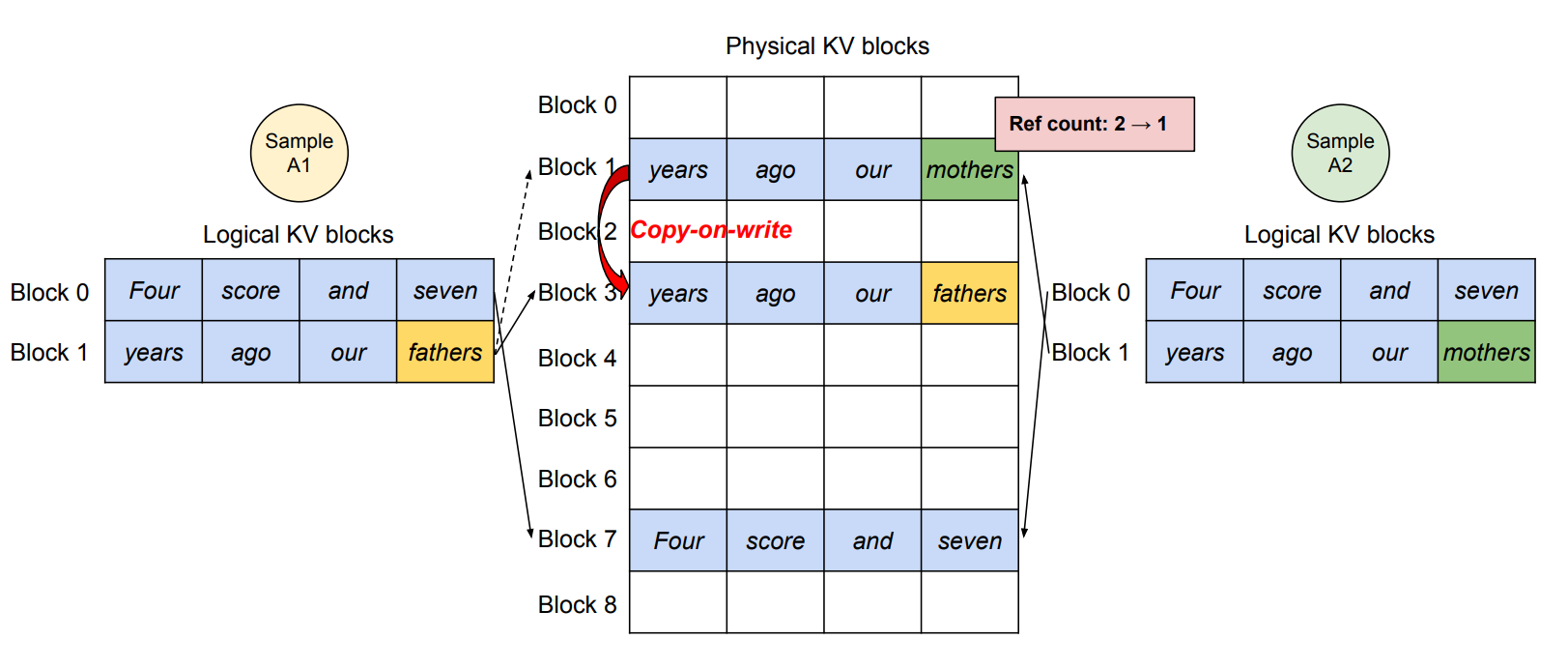
3.3.1 并行采样(Parallel Sampling)
当需要为同一个prompt生成多个不同的响应时:
1 | 请求: "写一首关于春天的诗" |
通过**写时复制(Copy-on-Write)**机制,多个生成序列可以共享相同prompt的KV块。
3.3.2 Beam Search
在Beam Search中,多个候选序列共享大部分前缀KV Cache:
1 | Beam 1: "春天来了" → "万物复苏" |
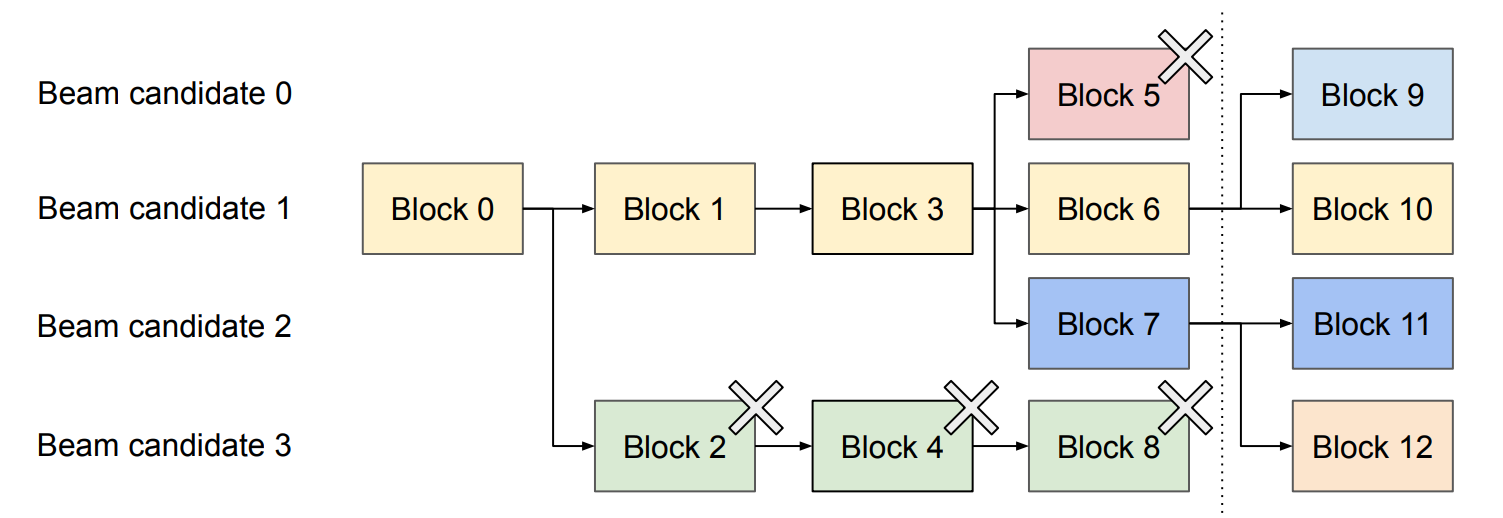
3.3.3 共享系统Prompt
多个用户请求可能共享相同的系统提示词:
1 | System Prompt: "你是一个helpful的AI助手..." |
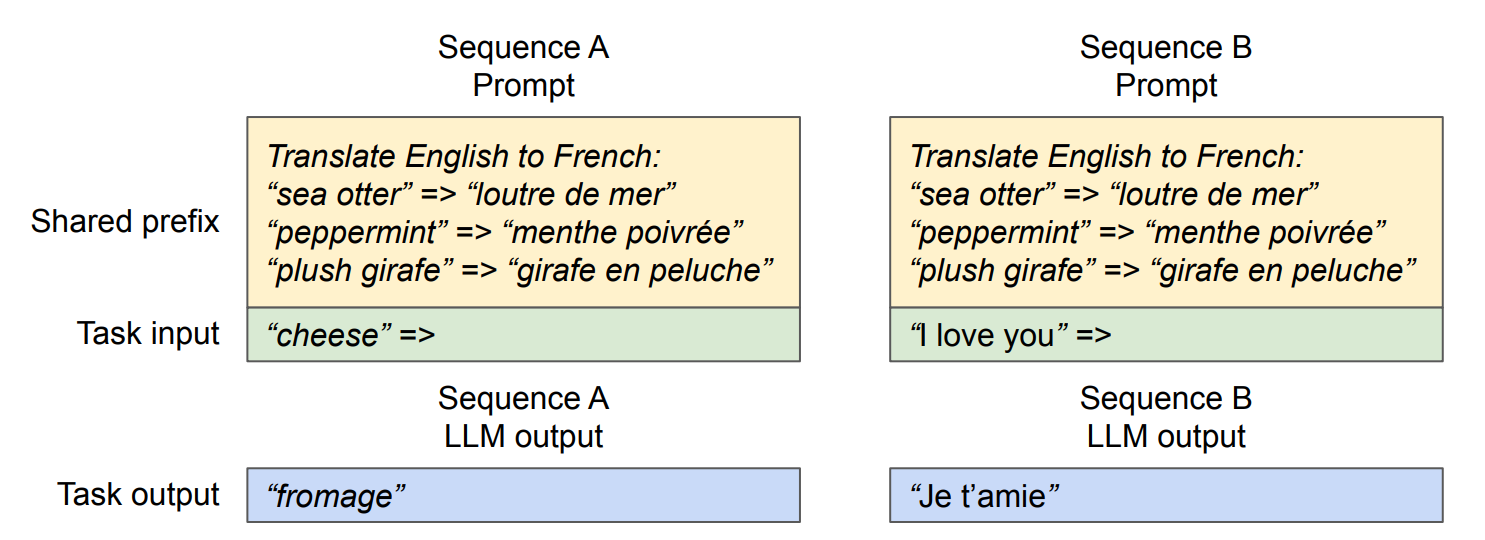
3.4 支持长上下文
- 无需预分配连续大内存块
- 可以处理远超单次分配限制的超长序列
- 动态扩展,按需增长
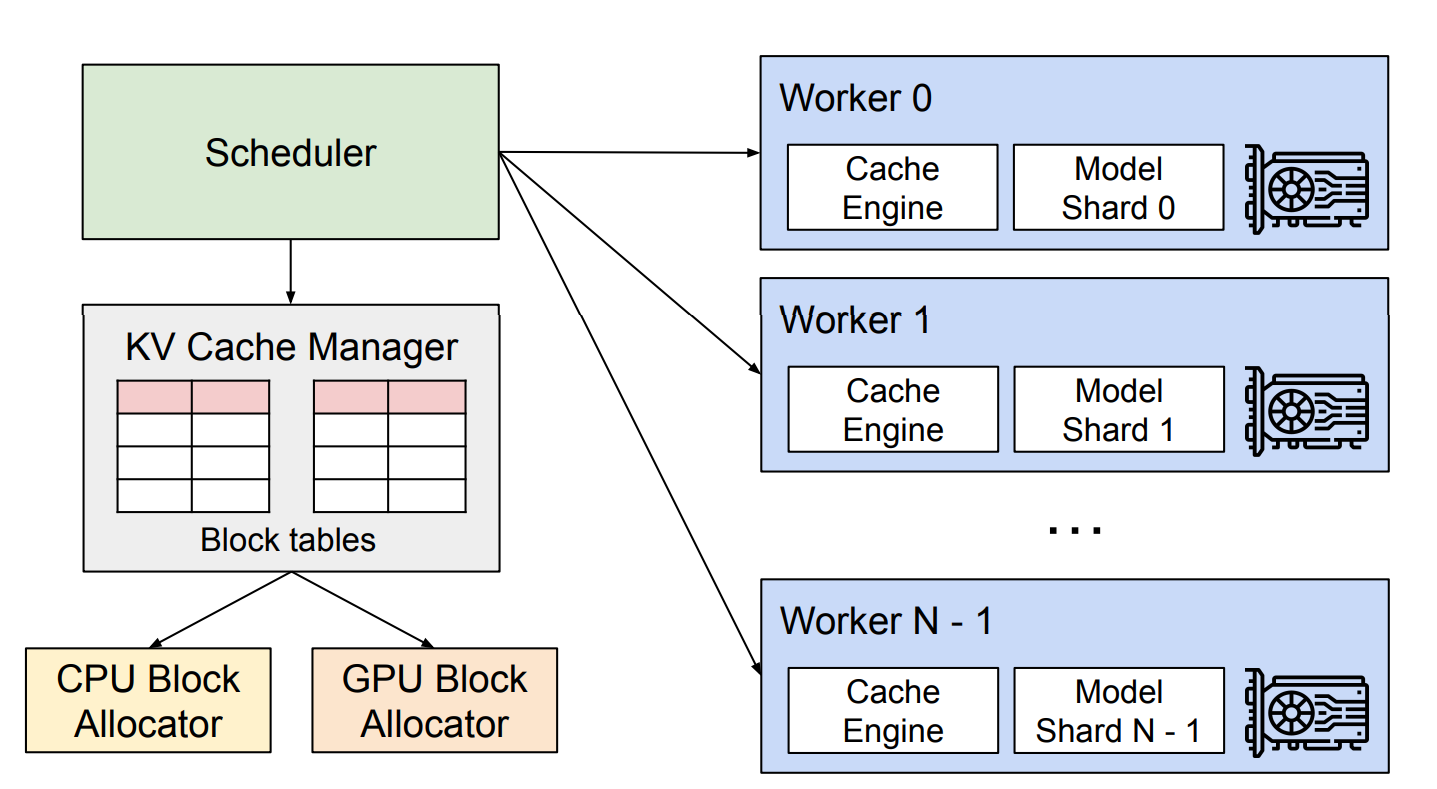
四、vLLM:PagedAttention的工程实现
4.1 vLLM架构概述
vLLM是首个基于PagedAttention的开源LLM推理引擎,实现了:
1 | ┌─────────────────────────────────────┐ |
4.2 KV Cache Manager
核心功能:
- 块池管理:维护可用物理块的池
- 块分配:为新token分配块
- 块回收:释放完成请求的块
- 引用计数:支持块共享的引用计数机制
1 | # vLLM块管理器简化示例 |
4.3 自动前缀缓存
vLLM实现了**自动前缀缓存(Automatic Prefix Caching)**功能:
- 使用哈希表管理KV块
- 自动检测和复用相同的前缀
- 无需用户手动指定
1 | # 自动前缀缓存原理 |
4.4 调度策略
vLLM支持多种调度策略:
- FCFS(First-Come-First-Serve):先到先服务
- 优先级调度:根据请求优先级
- 抢占和交换:内存不足时可以将部分请求的KV Cache交换到CPU
五、技术细节与实现要点
5.1 块大小的选择
块大小的权衡:
-
较小块(如16 tokens):
- ✅ 内存碎片更少
- ❌ 块表开销大,查找次数多
-
较大块(如128 tokens):
- ✅ 块表开销小
- ❌ 最后一块可能浪费较多
实践中通常选择16-64之间
5.2 CUDA Kernel优化
PagedAttention需要高效的CUDA kernel来处理非连续内存访问:
1 | // PagedAttention CUDA Kernel简化示例 |
5.3 内存预算与OOM处理
1 | # 内存管理策略 |
六、与其他优化技术的对比
6.1 Flash Attention
| 特性 | Flash Attention | PagedAttention |
|---|---|---|
| 优化目标 | 计算效率(减少HBM访问) | 内存管理效率 |
| 主要技术 | Tiling + 重计算 | 块状内存分配 |
| 加速场景 | 训练 & 推理 | 主要用于推理 |
| 是否兼容 | ✅ 可结合使用 | ✅ 可结合使用 |
两者可以结合:vLLM可以同时使用Flash Attention和PagedAttention!
6.2 量化技术(INT8/INT4)
| 特性 | 量化 | PagedAttention |
|---|---|---|
| 优化维度 | 减少每个参数的存储位数 | 优化内存分配方式 |
| 内存节省 | 模型权重和激活 | KV Cache |
| 是否互补 | ✅ 高度互补 | ✅ 高度互补 |
6.3 推测解码(Speculative Decoding)
PagedAttention与推测解码也可结合:
- 推测解码:通过小模型加速生成
- PagedAttention:提升内存利用率和吞吐量
七、总结
PagedAttention是大语言模型推理领域的一项重要创新:
核心贡献
- ✅ 近乎零浪费的内存管理:将浪费率从60-80%降低到<4%
- ✅ 显著的吞吐量提升:2-24倍的性能提升
- ✅ 灵活的KV共享机制:支持并行采样、Beam Search等复杂场景
- ✅ 工程化落地:vLLM已成为业界主流推理引擎
参考资料
- 原始论文:“Efficient Memory Management for Large Language Model Serving with PagedAttention” (2023)
- vLLM GitHub: https://github.com/vllm-project/vllm
- vLLM官方文档: https://docs.vllm.ai/
- PagedAttention博客系列(多个技术博客)


